
Genie 3: review técnico, aplicações e impacto
- Pedro dos Santos
- há 21 horas
- 7 min de leitura

Resumo rápido: Genie 3 é o mais recente world model da Google DeepMind: um modelo generativo capaz de criar ambientes 3D interativos a partir de uma imagem ou de um comando em linguagem natural. Este review explica como o Genie 3 funciona, para que serve, quais são suas forças e limitações, implicações práticas (jogos, treinamento de agentes, simulações industriais) e riscos.
O que é genie 3? (definição simples)
Genie 3 é um modelo de mundo (world model) criado pela Google DeepMind que gera ambientes virtuais navegáveis em tempo real a partir de texto ou imagens. Diferente de um gerador de imagens ou de vídeos passivos, um world model tenta representar a dinâmica do ambiente: física simples, relações espaciais e a possibilidade de interação contínua, permitindo que usuários ou agentes andem, saltem, observem e modifiquem o mundo por vários minutos.

Por que isso é importante? (visão macro)
Modelos como o genie 3 representam uma mudança no paradigma de geração multimodal: saímos de respostas estáticas (imagem, vídeo) para modelos que podem simular ambientes com consistência temporal e reatividade. Isso abre portas para:
Treino virtual de robôs e agentes por simulação (economia de custo/segurança).
Ferramentas de prototipagem para designers e desenvolvedores de jogos.
Produção de experiências educativas e imersivas (turismo virtual, educação científica).
Essas aplicações não são teoria: DeepMind posiciona world models como infra essencial para agentes que aprendem por interação, e o Genie 3 foi projetado exatamente para esse uso.
Como o genie 3 funciona: explicação técnica acessível
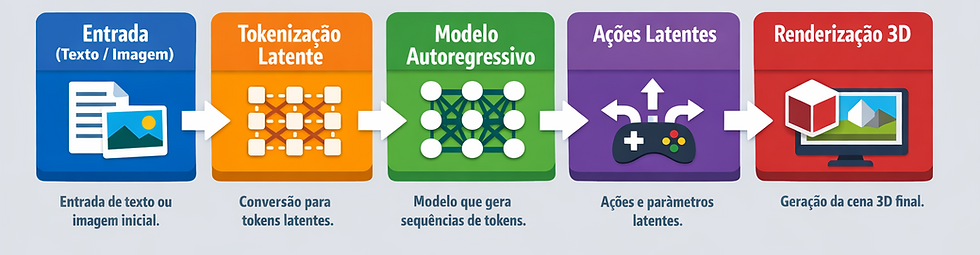
Aqui descrevo, em linguagem clara, os elementos técnicos principais por trás de modelos como Genie (e sua evolução até o Genie 3). Vou separar em camadas para ficar mais didático.
Dados e treinamento
Genie e variantes foram treinados com enormes quantidades de vídeo e gravações de jogos para aprender padrões espaciais e temporais. No paper original do projeto Genie a equipe treinou com centenas de milhares de horas de vídeo (ex.: vídeos de gameplay) para que o modelo aprenda relações espaço-temporais sem rótulos de ação explícitos. Isso permite aprender "o que acontece quando eu ando para frente" apenas observando.
Representação latente e tokenização
Em vez de gerar pixels diretamente frame a frame, o sistema converte frames e vídeos em representações latentes (tokens compressos), que capturam informação visual e temporal de forma densa. Esses tokens são a linguagem interna do modelo. A geração e o controle (ações do usuário) são feitos manipulando esses tokens. (Isto é paralelo ao que Veo e outros modelos de vídeo usam com autoencoders e latentes).
Modelagem de dinâmica e “ações latentes”
Genie introduziu uma interface de ações latentes: em vez de exigir rótulos “pular”, “andar” durante o treino, o modelo aprende uma parametrização de ações derivada dos próprios dados (ações latentes) que permitem controlar o ambiente gerado. Isso é o que possibilita interagir com o mundo de forma contínua mesmo sem ter visto exatamente essa ação rotulada antes.
Autoregressão e capacidade de memória
Modelos como Genie 3 usam arquiteturas auto-regressivas (transformers) que preveem o próximo token condicionado no histórico: isso dá coerência temporal. Genie 3 escalou essas ideias para interação em tempo real (24 fps a ~720p em demos) e aumentou o chamado interaction horizon, a duração de tempo em que o ambiente permanece consistente.
Diferença entre world models e modelos de vídeo (Veo, Sora, etc.)
Modelos de vídeo (por exemplo, Veo 3) focam em gerar clipes realistas (difusão em latentes), ótimo para produção de conteúdo audiovisual, mas tipicamente não são desenhados para contínua interação controlável por um agente humano em tempo real. Genie 3, em contraste, é otimizado para simulação interativa, com respostas incrementais às ações do usuário. Ambos são complementares e compartilham técnicas (latentes, transformers), mas têm objetivos distintos.
Principais capacidades (o que o genie 3 faz bem)
Geração de mundos 3D a partir de texto ou imagem: descreva “uma vila costeira com farol”, o modelo cria um ambiente explorável.
Interação em tempo real: navegável com controles simples e mudanças aplicadas ao ambiente persistem por um tempo (pintura em parede, posições de objetos).
Consistência espacial e física aprendida: o modelo tende a manter propriedades físicas (gravidade simples, colisões plausíveis) por períodos mais longos que iterações anteriores.
Promptable world events: é possível alterar o clima, adicionar personagens ou objetos ao vivo via prompt.
Essas capacidades foram destacadas nas demonstrações públicas e no protótipo chamado Project Genie (acessível a um grupo restrito/assinantes), que usa o Genie 3 como backend.

Limitações e problemas atuais (transparência)
Apesar do avanço, Genie 3 ainda apresenta restrições práticas e técnicas:
Fidelidade visual limitada para uso cinematográfico: demos rodam a ~720p e não alcançam qualidade fotorealista absoluta comparada a cenas filmadas.
Limitação de duração e consistência longa: o interaction horizon aumentou para minutos, mas mundos extremamente longos e complexos ainda mostram degradação e inconsistências de texto/legibilidade.
Controles e jogabilidade básicos: interação com personagens e controles de jogo ainda são rudimentares, portanto não substituem um motor de jogo profissional para títulos complexos.
Riscos de propriedade intelectual e deepfakes: geração de mundos que se parecem com franquias famosas ou cenas reais pode levar a problemas de copyright e de desinformação, como já discutido para modelos de vídeo similares (ex.: Veo 3).
Comparações rápidas com tecnologias relacionadas
Veo 3 (DeepMind / Google): foca em geração de vídeo de alta fidelidade (clips), com capacidades multimodais (áudio + vídeo). Veo é mais forte para produção de conteúdo estático/linear; Genie 3 é forte em simulação interativa.
Modelos de vídeo de mercado (OpenAI Sora / Runway / Meta): muitos investem em realismo e controle frame-wise; a diferença-chave é que world models visam controle contínuo e física plausível para interação. (ver discussões em publicações técnicas e coberturas jornalísticas).
Aplicações práticas: 9 usos com exemplos
Prototipagem de níveis para jogos: designers descrevem um cenário e rapidamente andam pelo nível para avaliar escala e jogabilidade. (economia de tempo de iteração).
Treino de robôs e logística: simulações de armazéns para treinar trajetórias e políticas de navegação sem risco físico.
Testes de agentes de IA: agentes virtuais podem ser treinados por tentativa e erro em ambientes infinitos gerados por prompts.
Educação imersiva: laboratórios virtuais replicando experimentos de física ou biologia que alunos podem explorar.
Arquitetura e visualização: walkthroughs interativos para clientes verem propostas de projeto em escala humana.
Conteúdo de marketing e experiências de marca: experiências curtas interativas para campanhas.
Pesquisa e desenvolvimento: testbed para estudar aprendizagem de controle, planejamento ou modelos de mundo.
Storytelling e animação rápida: prototipagem de cenas e cenários para roteiristas.
Acessibilidade: simulações usadas para criar tours virtuais para pessoas com mobilidade reduzida.

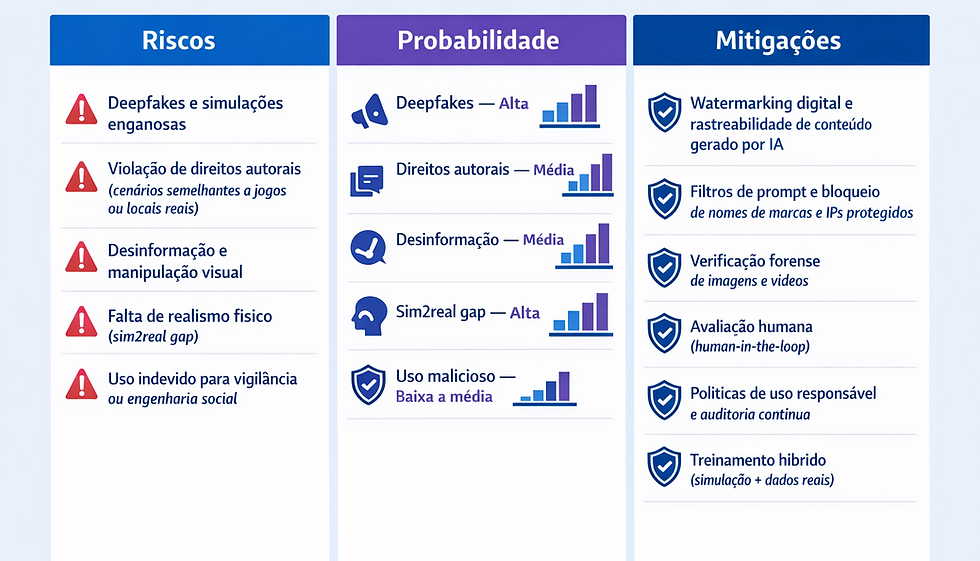
Questões éticas, legais e de segurança
Modelos de mundo apresentam riscos específicos:
Desinformação / deepfakes: mundos gerados que retratem eventos políticos ou reais podem ser usados para enganar. Ferramentas de detecção precisam evoluir em paralelo.
Copyright e conteúdo inspirado em IP existente: a geração pode replicar estilos ou ambientes proprietários (ex.: jogos famosos), gerando disputas legais.
Privacidade: mundos baseados em imagens reais podem expor ou reconstruir locais/identidades.
Dependência tecnológica: treinar agentes só em simulações pode introduzir vieses de simulação (sim2real gap), agentes treinados exclusivamente em mundos artificiais podem não transferir bem para o mundo físico. Pesquisadores alertam para a necessidade de validação em ambientes reais.
DeepMind e outras empresas publicaram medidas de mitigação (conteúdo restrito, análises de risco, testes com grupos controlados) como parte de um processo de lançamento controlado.
Como testar hoje (acesso e protótipo)
Em janeiro de 2026 a Google lançou o Project Genie, um protótipo experimental baseado em Genie 3 acessível a assinantes de determinados planos (ex.: AI Ultra) e via demo controlada, inicialmente restrito geograficamente e por convite. Para experimentar, há um frontend de exploração (navegação via WASD) e ferramentas de remixagem de mundos.
Observação: o estado do acesso público muda rapidamente, verifique o blog oficial da DeepMind e o Project Genie para atualizações.
Recomendação técnica para equipes (developers / CTOs)
Se você pensa em integrar world models como o genie 3 em produtos, siga estas práticas:
Defina casos de uso bem delimitados: prototipagem, simulação de agentes, demonstrações imersivas. Evite substituir pipelines de produção de mídia até a fidelidade estar adequada.
Avalie o sim2real gap: valide que agentes treinados na simulação transferem para o mundo real com testes intermediários.
Arquitetura híbrida: combine world models com motores tradicionais (Unity/Unreal) quando for necessária física complexa ou suporte multiplayer robusto.
Política de uso e filtragem: implemente limitações para evitar geração de conteúdo que viole IP ou políticas internas.
Referências e leituras recomendadas (seleção técnica)
DeepMind: post oficial “Genie 3: A new frontier for world models” (blog DeepMind).
Paper “Genie: Generative Interactive Environments” (arXiv, 2024): detalha a arquitetura inicial e o conceito de ações latentes.
The Verge: cobertura e hands-on com Project Genie (comentários de usabilidade e limitações).
Ars Technica: artigo sobre lançamento e implicações.
DeepMind Veo 3: tech report e discussões sobre modelos de vídeo para comparação.
The Guardian: análise do impacto de world models para aplicações robóticas e debates sobre AGI.
Glossário rápido (termos técnicos explicados)
World model (modelo de mundo): modelo que tenta representar não só imagens, mas a dinâmica do ambiente (como objetos se movem, como a física se aplica).
Latente / representação latente: versão compacta dos dados (imagens/vídeos) que retém informações essenciais sem ocupar tantos bytes quanto pixels brutos.
Autoregressivo: arquitetura que prevê o próximo token condicionado ao histórico (útil para manter coerência temporal).
Interaction horizon: janela temporal na qual o ambiente permanece coerente e responsivo às ações do usuário.
Conclusão: avaliação final (resumo do review)
Avaliação resumida: o genie 3 é um avanço marcante na pesquisa de world models: oferece simulações interativas, consistência temporal maior e interface de prompt que o torna valioso para prototipagem, pesquisa e treinamento de agentes. Para produtos comerciais maduros (jogos AAA, produção cinematográfica), ainda falta fidelidade e ferramentas de controle mais avançadas, mas para equipes de P&D, startups e estúdios indie que buscam iterar rápido, Genie 3 e sua integração via Project Genie representam uma ferramenta estratégica.
Quer aplicar agentes de IA e automações inteligentes no seu negócio?
Fale com nossos especialistas e descubra como transformar seus processos com tecnologia de ponta. Podemos: avaliar seu cenário atual, projetar uma arquitetura segura (Zapier, Make, n8n ou Langgraph), prototipar um agente piloto conectado aos seus sistemas e medir ROI em semanas.



Comentários